Text-to-speech and vocal generation
Generate speech from text, including spoken delivery and other audio styles shown on the site such as singing and rapping.
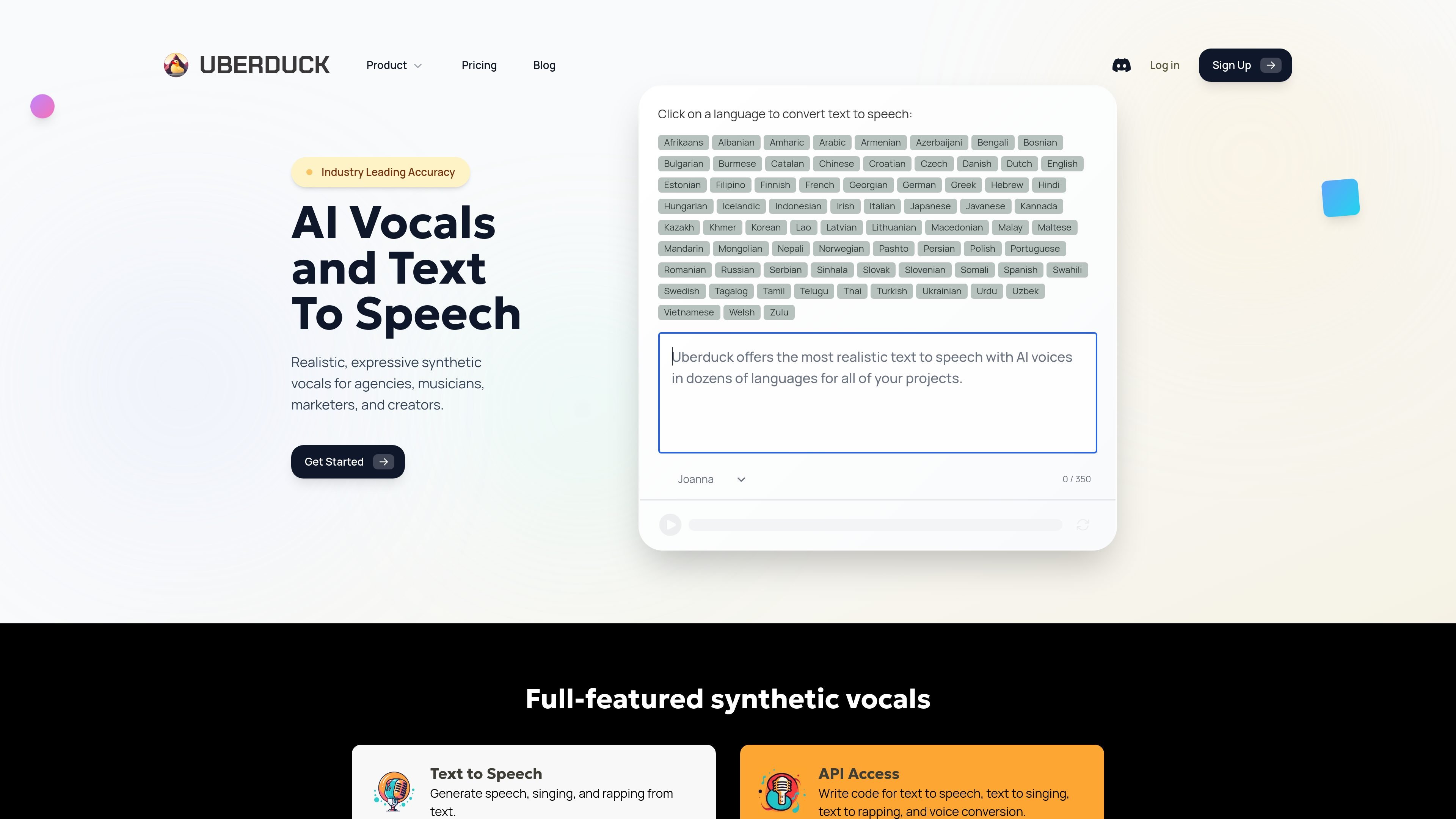
Uberduck is an AI voice and music platform for generating speech, singing, rapping, and voice conversion from text or cloned voices. Its homepage positions the product for agencies, musicians, marketers, and creators who need synthetic vocals for voiceovers, media, and audio production.
The product site also includes AI music generation and a free text-to-speech experience, giving users a browser-based workflow for trying voices, cloning a voice, or generating songs. Paid plans add commercial usage and premium features, while the site also exposes API access for teams that want to build with voice generation programmatically.
Generate speech from text, including spoken delivery and other audio styles shown on the site such as singing and rapping.
Create custom voices by cloning from a microphone recording or an audio file, then use those voices for speech or voice conversion.
Convert one voice into another while preserving the style of the original performance, according to the product page.
Produce AI music from prompts, with examples spanning songs, jingles, themes, and background tracks.
Use the platform programmatically through API access for text to speech, text to singing, text to rapping, and voice conversion.
Choose from many languages and a wide voice catalog, including named voices on the text-to-speech page.
Write a script and turn it into spoken audio for narration, voiceovers, or other narrated content without recording a human voice.
Record a voice sample or upload audio, then reuse the cloned voice for podcasts, ad reads, audiobooks, or character work.
Generate songs, jingles, and background tracks for social posts, videos, game projects, or branded audio assets.
Use the API to automate text-to-speech, text-to-singing, text-to-rapping, or voice conversion inside a custom product or workflow.
Try multilingual voices and different voice styles when producing content for international or voice-led experiences.
Uberduck is a web-based AI voice tool for text to speech, voice cloning, speech-to-speech voice conversion, and AI music generation. The site also presents API access for programmatic text-to-speech, singing, rapping, and voice conversion.
The site says voice cloning can be created from a microphone recording or an audio file, and that the process is fast and simple. It also highlights mobile-friendly creation.
Uberduck supports text-to-speech in many languages and exposes a large voice library on its TTS page. The site lists dozens of supported languages across its product pages.
The pricing page shows paid plans for Starter, Creator, and Pro. Creator and Pro include commercial licensing, while Starter is labeled as a non-commercial license.
The site includes FAQ headings about voice cloning legality, security, support, and commercial use, but the rendered text does not provide full written answers for each item.
Vocloner is a web-based AI voice cloning tool that lets users create a custom voice from an audio sample and generate speech with it. The site highlights multilingual output, inline emotion tags, and a free tier with usage limits.
SongMuse is a browser-based AI music generator that turns short prompts into songs or instrumental tracks for royalty-free use under plan terms. It supports lyrics, vocals, production controls, and MP3 downloads for creators working on social content, demos, podcasts, games, and personal projects.
Voice Generator is a free browser-based text-to-speech web app that turns typed text into spoken audio. It lets you play or download the result, with pitch and speed controls and offline use when compatible voices are installed.
Free Text to Speech Online is a web-based AI voice generator that converts text into speech, supports many languages, and lets users preview and download audio. It offers a free plan, paid tiers for heavier use, and email support.
PixMagic is a browser-based AI studio for image generation, editing, upscaling, background removal, image-to-video, and text-to-speech. It uses one-time credit recharges instead of a subscription and offers 10 trial credits for new users.
TTSReader is a browser-based text-to-speech tool for reading text, documents, PDFs, ebooks, and webpages aloud. It also supports MP3 export, multilingual voices, and pronunciation controls for offline listening, sharing, and publishing workflows.